
Flume
Documentazione di riferimento: https://flume.apache.org/FlumeUserGuide.html#flume-sources
Apache Flume e' un servizio distribuito affidabile e disponibile per la raccolta, l'aggregazione e il trasporto un grande quantitativo di dati di log in maniera efficiente. Ha un'architettura semplice e flessibile. E' un sistema robusto e tollerante al fallimento con meccanismi di impostazione dell'affidabilita' e di recupero dati. Usa un modello dati estensibile utile per applicazioni analitiche online.
Un evento Flume e' definito come un'unita' di flusso di dati con un payload di byte e un set facoltativo di attributi. Un agente Flume e' un processo (JVM) che ospita i componenti attraverso i quali gli eventi passano da un'origine esterna alla destinazione successiva.
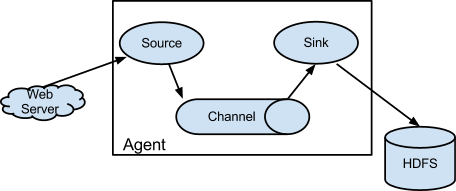
Una Flume source consuma eventi consegnati da una fonte esterna come un server web. La fonte esterna invia eventi a Flume in un formato riconosciuto dalla sorgente Flume di destinazione, ad esempio, una sorgente Avro Flume Quando una fonte Flume (Flume source) riceve un evento, lo memorizza uno o piu' canali. Il canale e' un archivio passivo che mantiene l'evento fino a quando non viene consumato da un sink Flume. Il canale per esempio e' il filesystem locale. Il sink rimuove l'evento dal canale e lo inserisce in un repository esterno come HDFS (tramite il sink Flume HDFS) o lo inoltra alla sorgente Flume del prossimo agent Flume nel flusso. Il source e il sink all'interno dell'agentvengono eseguiti in modo asincrono in riferimento ai dati inseriti e letti sul canale.
- Flume source: componente dell'agent in ascolto dell'evento
- Flume Channel: archivio dei singoli eventi
- Flume Sink: componente che consuma dal channel e archivia o passa ad altro source
Flume source elenco :
- Avro Source
- Thrift Source
- Exec Source
- JMS Source
- Spooling Directory Source
- Taildir Source
- Twitter 1% firehose Source (experimental)
- NetCat TCP
- Taildir Source
- Twitter 1% firehose Source (experimental)
- Kafka Source
- NetCat TCP Source
- NetCat UDP Source
- Sequence Generator Source
- Syslog Sources
- HTTP Source
- Stress Source
- Legacy Sources
- Custom Source
- Scribe Source
Flume Channels elenco:
- Memory Channel
- JDBC Channel
- Kafka Channel
- File Channel
- Spillable Memory Channel
- Pseudo Transaction Channel
- Custom Channel
Flume Sinks elenco:
- HDFS Sink
- Hive Sink
- Logger Sink
- Avro Sink
- Thrift Sink
- IRC Sink
- File Roll Sink
- Null Sink
- HBaseSinks
- MorphlineSolrSink
- ElasticSearchSink
- Kite Dataset Sink
- Kafka Sink
- HTTP Sink
- Custom Sink
Esempio:
Per attivare un agent dobbiamo creare un file di configurazione e avviare un processo con tale file.
File di configurazione (my.conf):
agent1.sources = file1 agent1.channels = chan1 agent1.sinks = hdfs1 # source agent1.sources.file1.type = exec agent1.sources.file1.command = tail -F /opt/gen_logs/logs/access.log agent1.sources.file1.channels = chan1 #channel agent1.channels.chan1.type = memory agent1.channels.chan1.capacity = 10000 agent1.channels.chan1.transactionCapacity = 1000 #skin agent1.sinks.hdfs1.type = hdfs agent1.sinks.hdfs1.channel = chan1 agent1.sinks.hdfs1.hdfs.path = /flume/logs agent1.sinks.hdfs1.hdfs.filePrefix = logs_
lanciare con:
flume-ng agent -n agent1 -f my.conf